B+树与数据库索引
曾经我有很多疑惑?
为啥表一般都有一个自增ID?
索引是什么?联合索引又是什么?
为什么要分表?这怎么上来就分100张啊
为什么删除数据磁盘空间也不会释放?
DBA让我回收碎片空间, 这咋回收呀?
答案都在b+树,把b+树和我们日常的数据库操作联系起来,就有一种一通百通的感觉
B+树
内存
随机读写
- 数组
- 哈希表
- 链表(跳表)
- 二叉树(AVL/红黑树…)
完全可以用内存实现一个关系数据库, 但是内存太贵了
磁盘
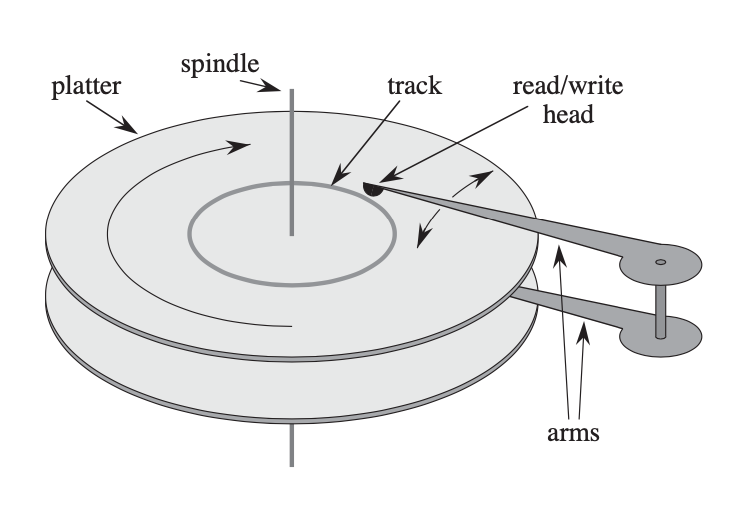
讲究一个量大管饱 读写数据需要先寻道,再按数据块(页)整体读取或写入.
闪存(SSD)
比磁盘快一个数量级
按数据块(页)整体读取或写入
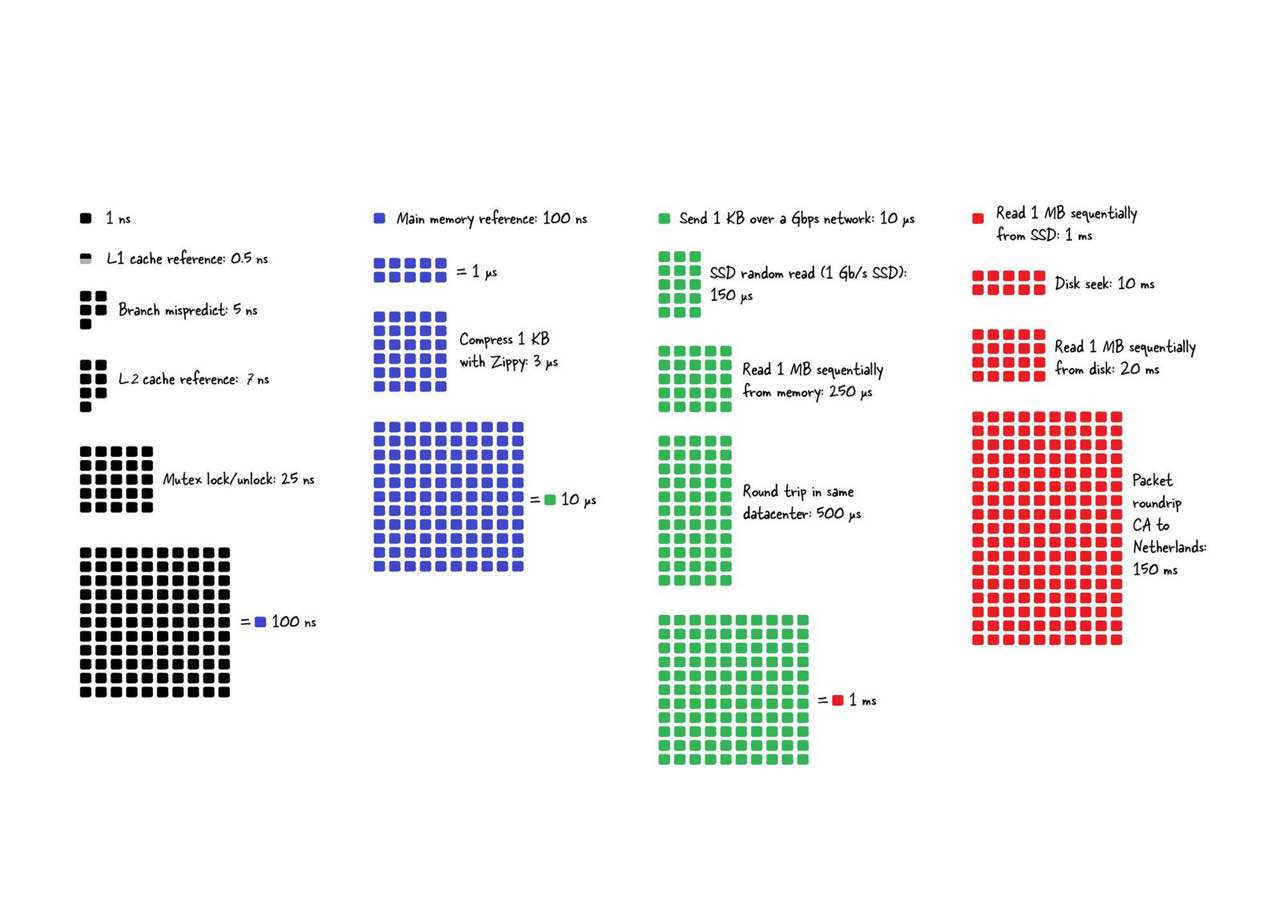
B+树的目标: 充分利用磁盘读写数据块 ,减少磁盘IO操作.
B树 Familly
- B Tree (1971)
- B+ Tree (1973)
- B link Tree (1981)
B+树
B+树是一个保持数据有序的绝对平衡的树形数据结构.
查找/顺序遍历/插入/删除 都是 O(logN).
- 类似二叉树,但是一个节点可以有多个子节点
- 专为读写块数据优化
B+树的属性
M路的搜索树
- 绝对平衡 (所有的叶子节点都在一层)
- 除了根节点,其他节点全部至少半满 M/2-1 ≤ #keys ≤ M-1
- 每一个有k个key的内部节点都会有k+1个子节点
Example:
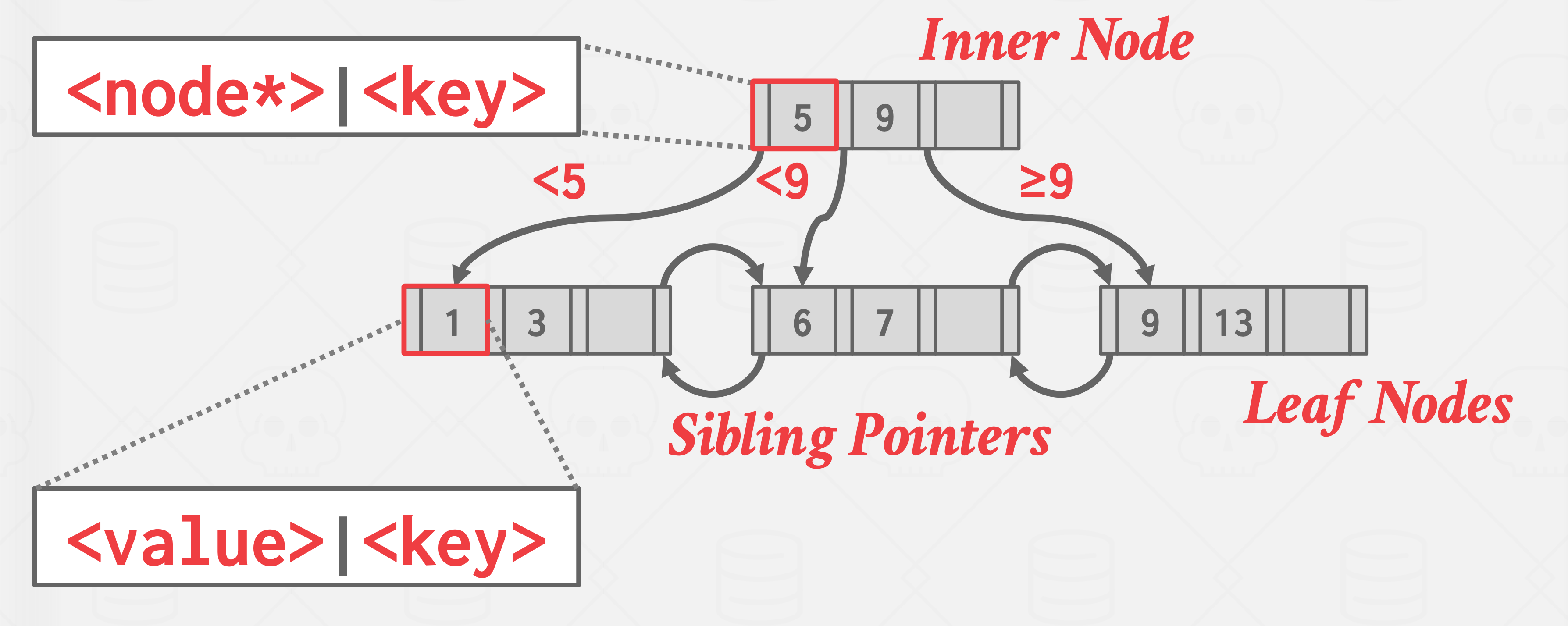
B+树节点
每个节点都由 key/value pair的数组组成
- key就是索引字段的属性值
- value 内部节点和叶子节点不同
数组通常使用key进行排序
B+树叶子节点
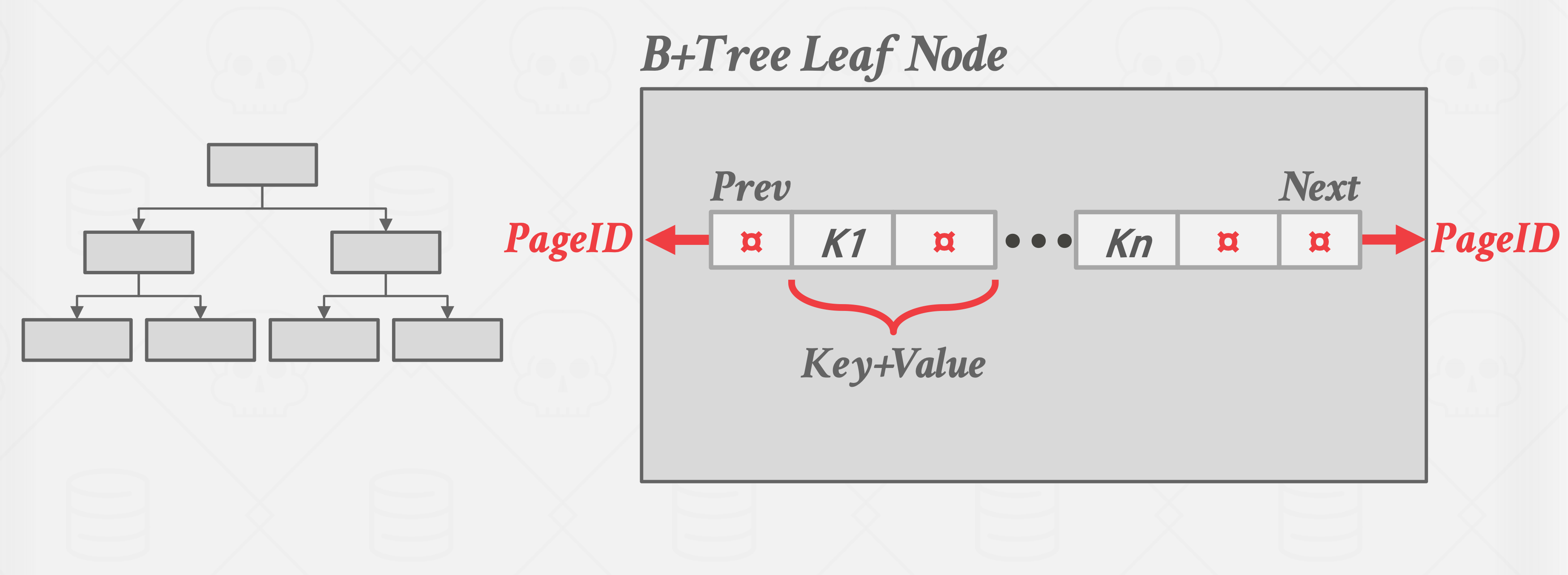
叶子节点的值

Innodb和B+树
聚簇索引(Clustered indexes)
| id | col |
|---|---|
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
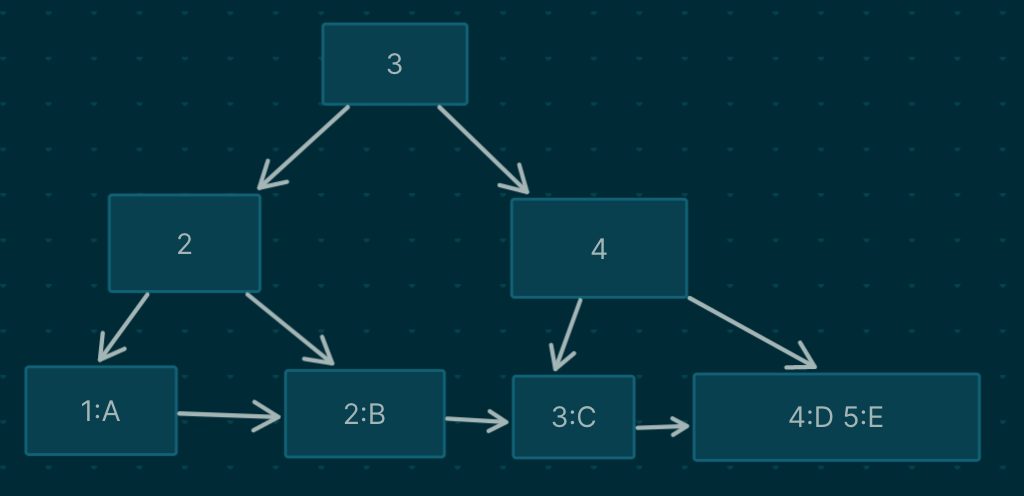
- 用来组织存储数据
- 表中的记录按照聚簇索引列顺序存储
- 通常主键就是聚簇索引
- 如果没有主键,INNODB用第一个唯一索引作为聚簇索引
- 如果没有主键也没有合适的唯一索引, INNODB生成一个一个row_id,作为隐藏的聚簇索引, 业务查询无法使用
- 自增ID是不错的选择
聚簇索引加速查询
- 可以直接定位到包含行数据的页, 不需要再读取额外的页
- 使用聚簇索引遍历数据 或者 order by
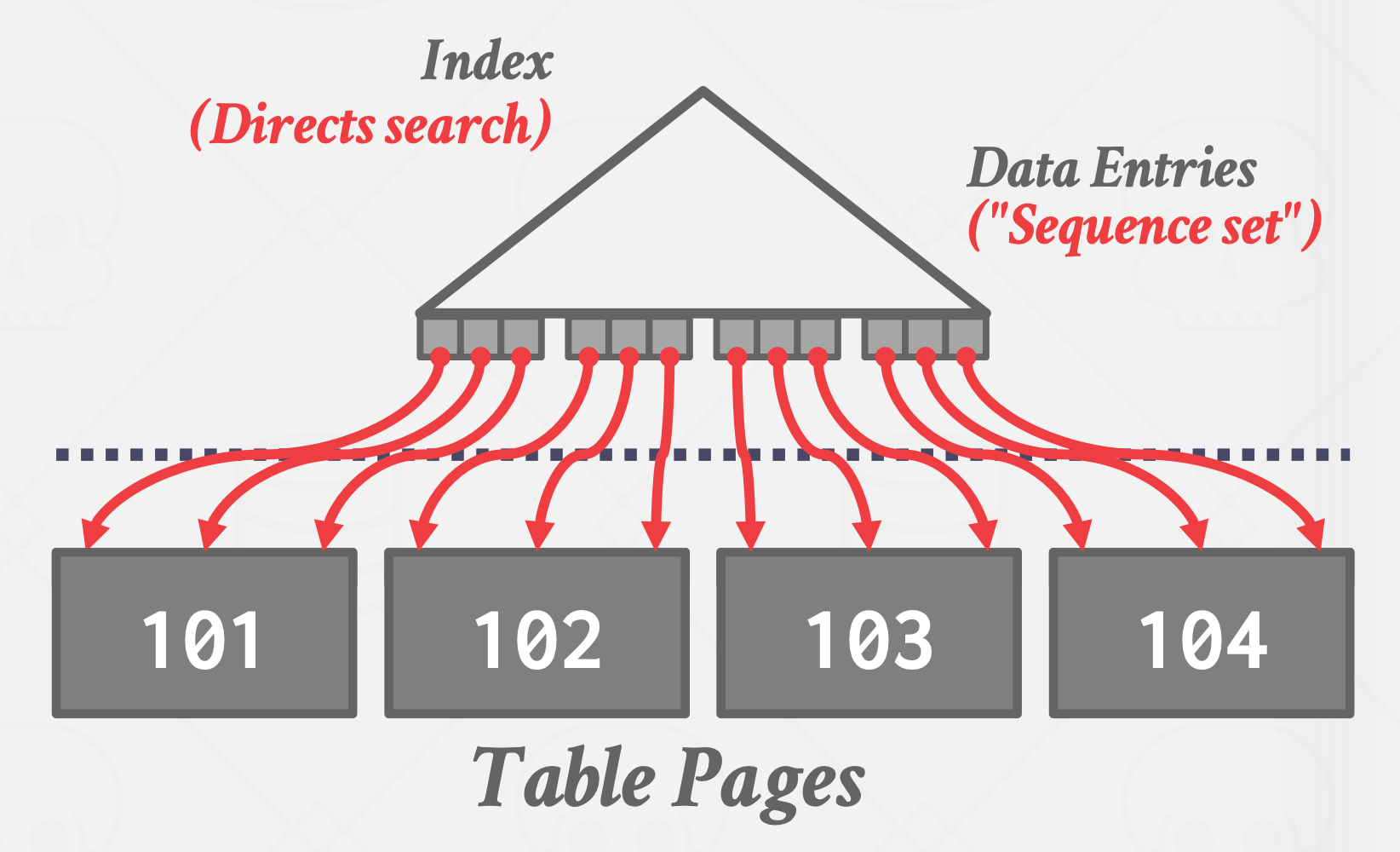
二级索引(Secondary indexes)
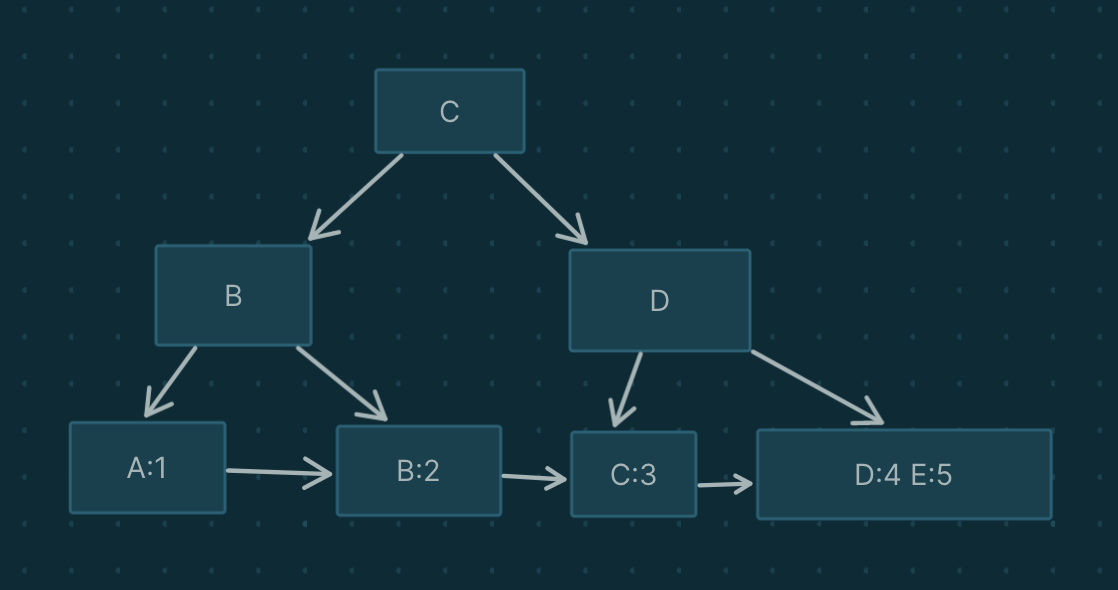
除了用来组织表数据的聚簇索引外的其他索引,统称为二级索引.
- INNODB中二级索引存储的值是聚簇索引的key
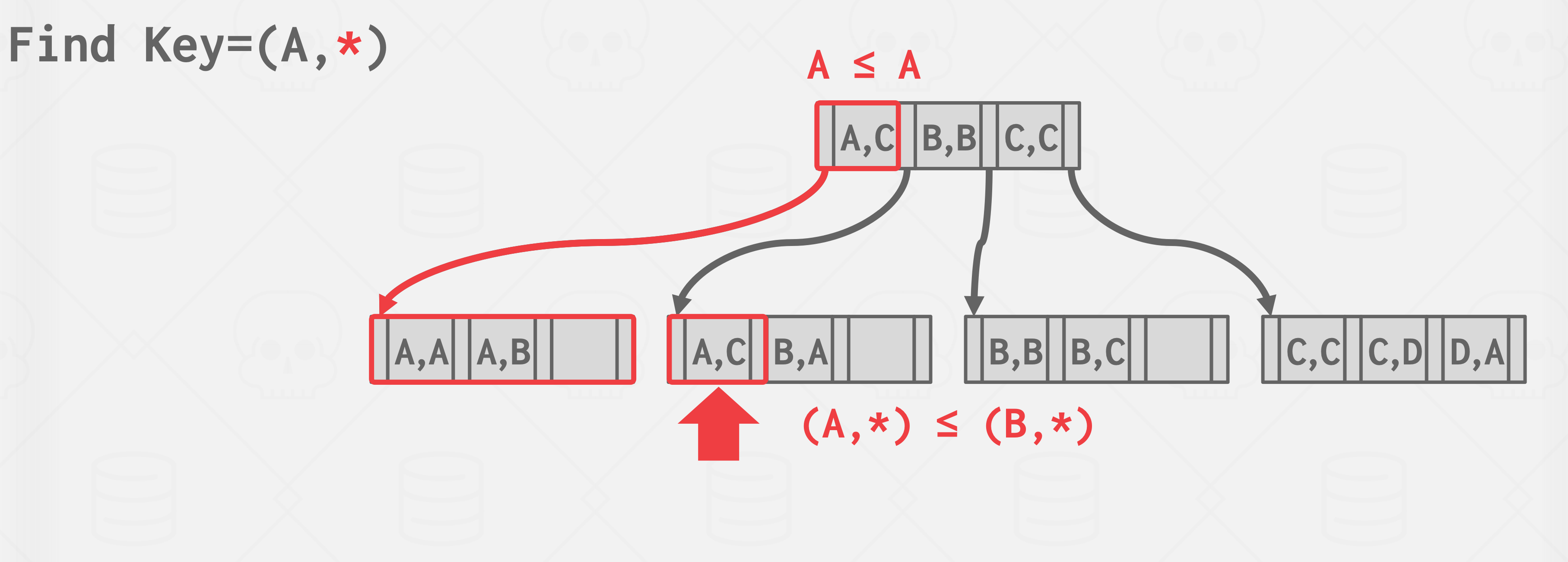
联合索引(Multiple-Column Indexes)
同时使用多个字段作为索引.
- mysql最多可以使用16个字段, 某些字段可以只取一部分前缀
- 可以使用联合索引查找符合所有索引字段的数据,或者符合第一个索引字段,或者前两个索引字段,或者前三个等等..
- 所以定义联合索引的先后顺序非常重要. 一个合适的联合索引可以加速多种查询场景
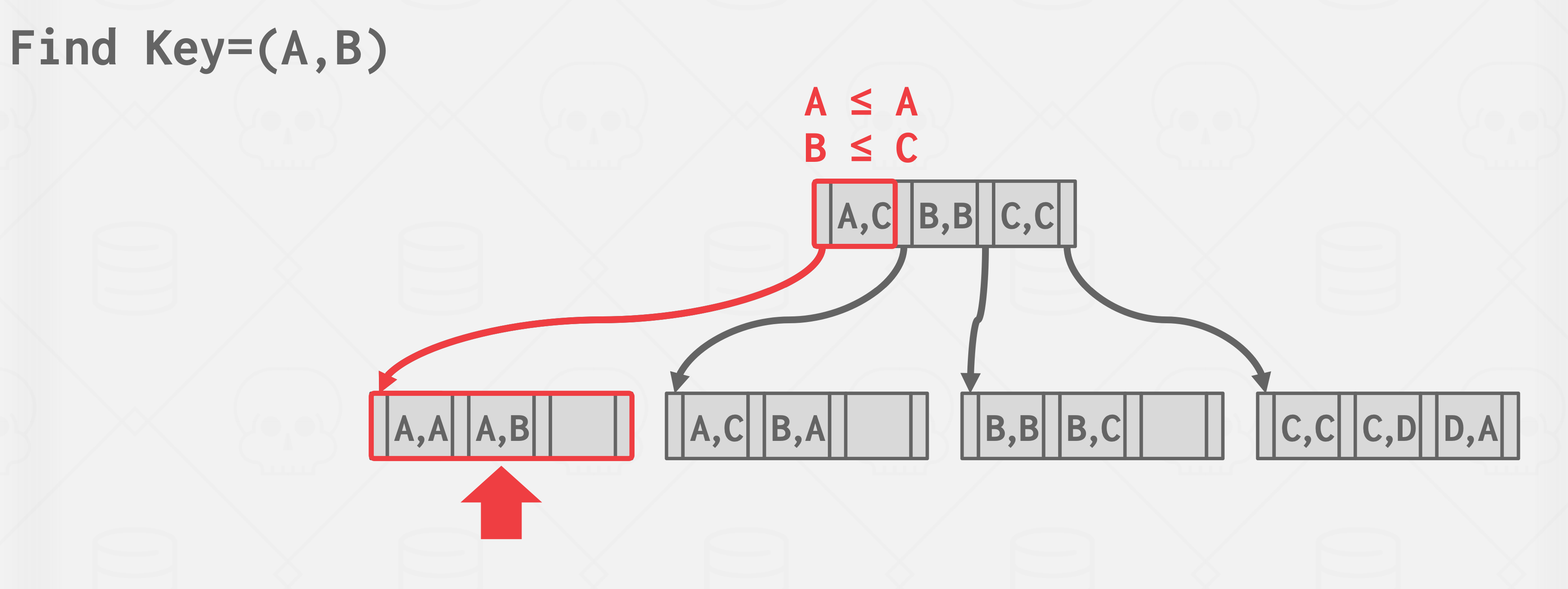
其他
分表
降低B+树高度,提高查询速度
$H = logM^N$
M 每个页可以存的数据行数
N 总数据量
以IM消息库为例:
page size 16k, . M = 100
分表 100张 - 每张表数据量约 3千万
H = log 100 ^ 30000000 = 6.2 约等于 3.7
如果不分表 单表数据量 30亿
H = log 100 ^ 3000000000 = 7.87 约等于 4.7
碎片整理
二级索引随机的数据插入或者删除都会导致索引数据碎片.
- 物理页的顺序和索引实际的顺序可能差的太多
- 页内存在很多没有使用的空间
ALTER TABLE tbl_name ENGINE=INNODB
对表进行重建
- 释放磁盘空间
- 重新按顺序组织索引数据在磁盘上分布
参考
- https://dev.mysql.com/doc/refman/5.7/en/innodb-indexes.html
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://dev.mysql.com/doc/refman/5.7/en/innodb-file-defragmenting.html
- https://dev.mysql.com/doc/refman/5.7/en/sorted-index-builds.html
- https://dichchankinh.com/~galles/visualization/BPlusTree.html
- https://15445.courses.cs.cmu.edu/fall2022/slides/08-trees.pdf